eBPF for All1
eBPF (Extended Berkley Packet Filtering) emerged a few times in my career dealings over the last couple of years, and I only now sat down to start taking it seriously. Whether on DFIR engagements or protecting some of the systems I use at my current employer, eBPF always plays a role in helping a user do some elegant things with the assistance of the kernel. But it’s not just my employer (and their operating system) teams that are exploring ways to make the Linux kernel work for them. So too is Facebook and Netflix and Apple and Splunk and DataDog and 5G Telco Networks even Cloudflare!
To make sure this article impacts the most people, here’s quick access for those at different starting points!
- I am super impatient and just want to see some cool things you can do with eBPF. Skip to “The Howto” section
- I sort of understand what eBPF is but I am curious about the more technical aspects of where it can be applied. Skip to “The Where” section
- I have no idea what eBPF is and want to fully immerse myself in everything. Read the whole article and make sure to follow all the people and blogs in “The Players” section at the bottom.
What’s Past is Prologue
TL;DR eBPF allows you to modify the kernel. Think of it as a highly efficient and safe way to inject custom logic into the kernel’s execution path- most of the time at least.
Before eBPF there was Berkeley Packet Filtering (BPF, aka cBPF). BPF was added as a feature to the Linux kernel in 1992 when the Lawrence Berkeley Laboratory2 implemented a pseudo-device that could be bound to a network interface enabling kernel-level packet capture. BPF was like tcpdump at the kernel level. Normally tcpdump works at the OSI Layers 2 through 4 where packets and segments are sent and received. Compared to BPF, tcpdump took relatively too much time to execute complex filters, and took too many CPU cycles to perform tasks. With BPF it could be thought of as the next evolution in network monitoring– analyzing network traffic at deeper layers, in the kernel.
Then in 2014, a group of Linux researchers decided to make the kernel more programable without inventing any revolutionary ideas at the risk of not being accepted by the Linux maintainers3. It was then the Linux community approved a new 64-bit virtual machine which evolved into an entire project focused on “extending” BPF4. The once lowly packet filter had grown into a fully event-driven engine; capable of monitoring and actioning upon system calls (tracepoints, kprobes, uprobes), network events (XDP and tc), and hardware events. This became eBPF, extended Berkeley Packet Filtering. No longer were BPF programs bound to just a host machine’s network interface, they could monitor process events now too. In some cases eBPF even helped alleviate DDOS attacks because it would more quickly drop incoming garbage data that could overload servers en masse.
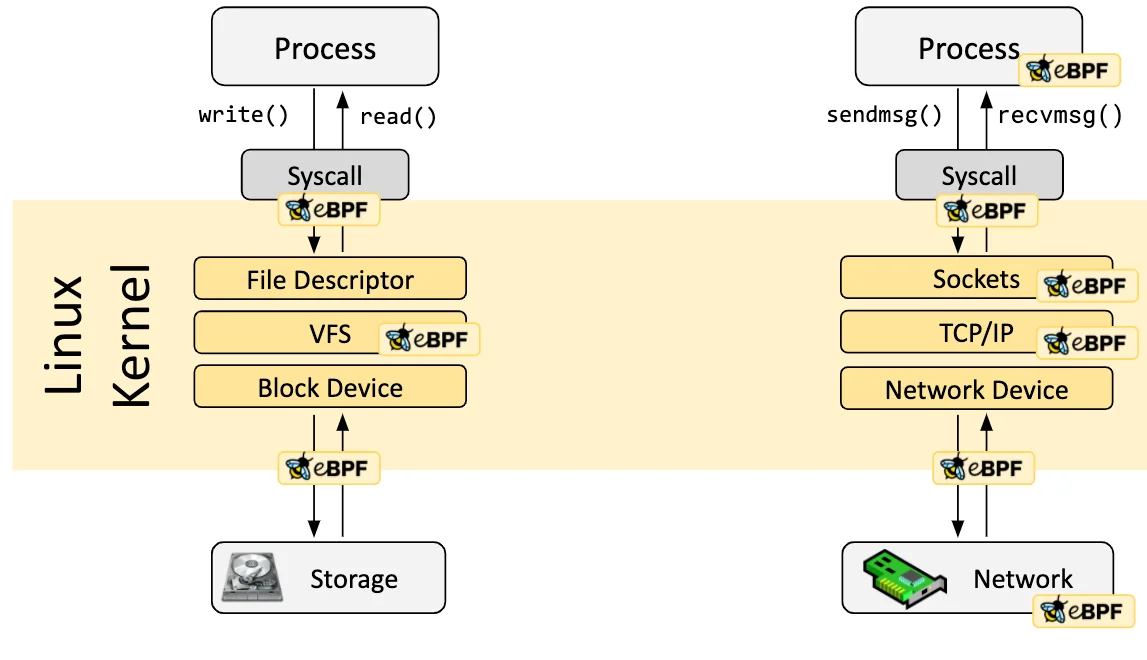 |
| All the places eBPF could hook itself |
Having this readily available in most Linux distributions in every kernel invited new possibilities for observability and monitoring at a more ground-truth level. Even more, this meant that any system running Linux had eBPF ready to use. That includes cloud and containerized solutions like Docker and Kubernetes.
The Why
Today eBPF is most recognizably found in the endpoint detection and response (EDR) tooling put on host machines; see table below. In light of this every threat detection engineer, SOC analyst, DFIR responder, Red Teamer, and CISO should start familiarizing themselves with this topic. Side note: eBPF is not just a Linux kernel advancement but it is found in Windows too!
| Security Product Name | Year of First Introduction (from sources found) | Source |
|---|---|---|
| Microsoft Defender for Endpoint (Linux) | March 2021 | Microsoft Defender for Endpoint Release Notes and Use eBPF-based sensor for MDE on Linux |
| VMware Carbon Black EDR | April 2021 | VMware Carbon Black EDR Release Notes |
| Red Canary (idk about this) | 2021 | Red Canary Blog on eBPF for Security |
| Traceable AI | July 3, 2023 | Traceable AI Release Notes |
| CrowdStrike Falcon | September 2020 | The Other Crowdstrike Outage |
| Bitdefender GravityZone | June 2021 | Gartner Magic Quadrant Report |
| SentinelOne Singularity XDR | January 2021 | SentinelOne’s What is eBPF |
| Elastic Security | December 2020 | A look under the hood at eBPF: A new way to monitor and secure your platforms |
eBPF is also used by large organizations like Netflix to track network performance and at Facebook to troubleshoot latency issues. Even within the Kubernetes network stack is eBPF a useful network transport tool. Less notably it is being used as a part of threat actors’ arsenals5.
Warning: I am still learning so please let me know if some of my statements are half-truths so I can make sure to include the rest of the truth!
The Where
So I mentioned eBPF could be found in the kernel but let us take a look at where exactly.
eBPF has program types6. Some of which related to the core networking hook programs like BPF_PROG_TYPE_SCHED_CLS or BPF_PROGR_TYPE_XDP, those are tc and XDP eBPF programs, respectively. These hooks interact at different logical layers of the kernel’s network data processing. The easiest way to visualize this is in the below diagram where eBPF interacts with iptables.
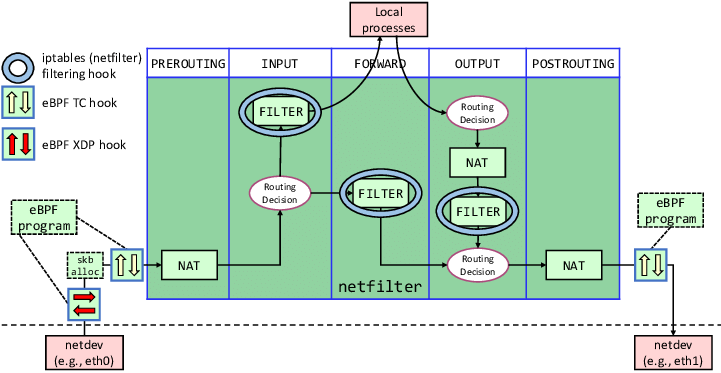 |
| Where eBPF interacts with iptables (nftables) |
Don’t worry if you aren’t familiar with how iptables work. For this article just understand that prior to eBPF a packet would first ingress to the prerouting table to begin processing what to do with it. Then on egress a packet would be last processed in the postrouting table before being sent out the correct network interface. With eBPF, processing and modification can happen even sooner or later depending on the programmer’s need. And this is just one of the many network things you could do with eBPF.
But as mentioned before eBPF can actually do so much more than just modify packets. I discussed above only some of the networking program types. We could also review the tracing program types to grab some perf statistics from all our running programs. Or how about something a tad more security oriented like recording process arguments as they are being executed in the kernel7; this would be the BPF_PROG_TYPE_KPROBE program type that uses Kprobes, kernel probes –there are also Uprobes (in userland) but that’s for another time.
The How
In order to interact with eBPF there are a couple different toolchains depending on the goal at hand. Some options are8 :
- Tracing: BCC (the old way), bpftrace, and others
- Networking: Cilium, Suricata, systemd, and others
- Security Monitoring Tools: Cilium’s Tetragon, Falco, tracee, and others
- Libraries: libbpf in C, ebpf-go, and Aya-rs in Rust
- bpftool for introspecting and debugging BPF programs from the command line
Bpftrace
Bpftrace is a great tool to get started on eBPF fast. It makes interacting with the kernel easy by using existing tracing capabilities like kprobes, uprobes, and tracepoints.
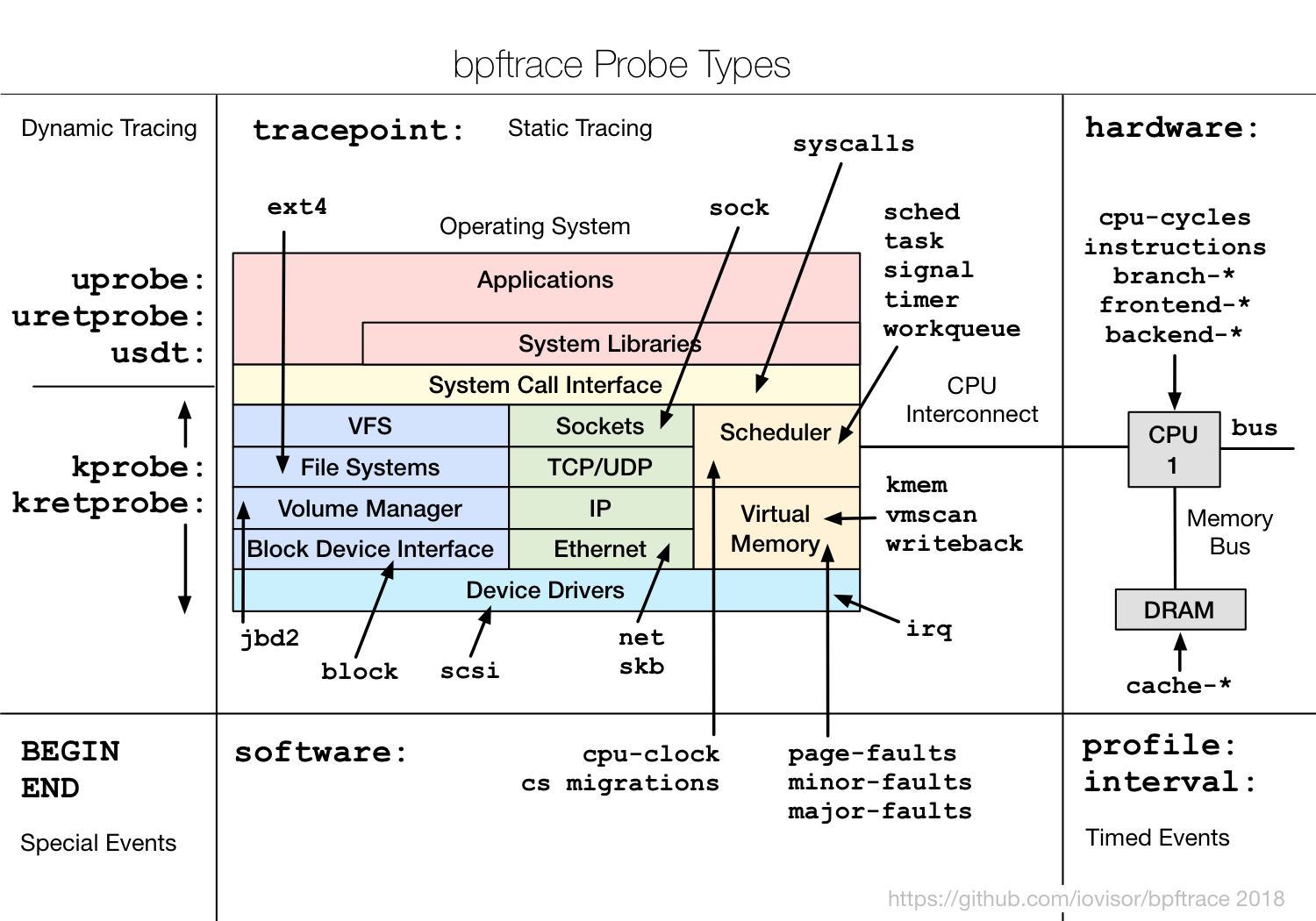 |
| Image of the various BPF probes available when developing with eBPF, source: https://github.com/bpftrace/bpftrace |
bpftrace -l: This command line tool seems to be the standard for debugging and introspection BPF programs. For example, if I want to list all the available Linux syscalls I could trace I would run #bpftrace -l 'tracepoint:syscalls:sys_enter_*':
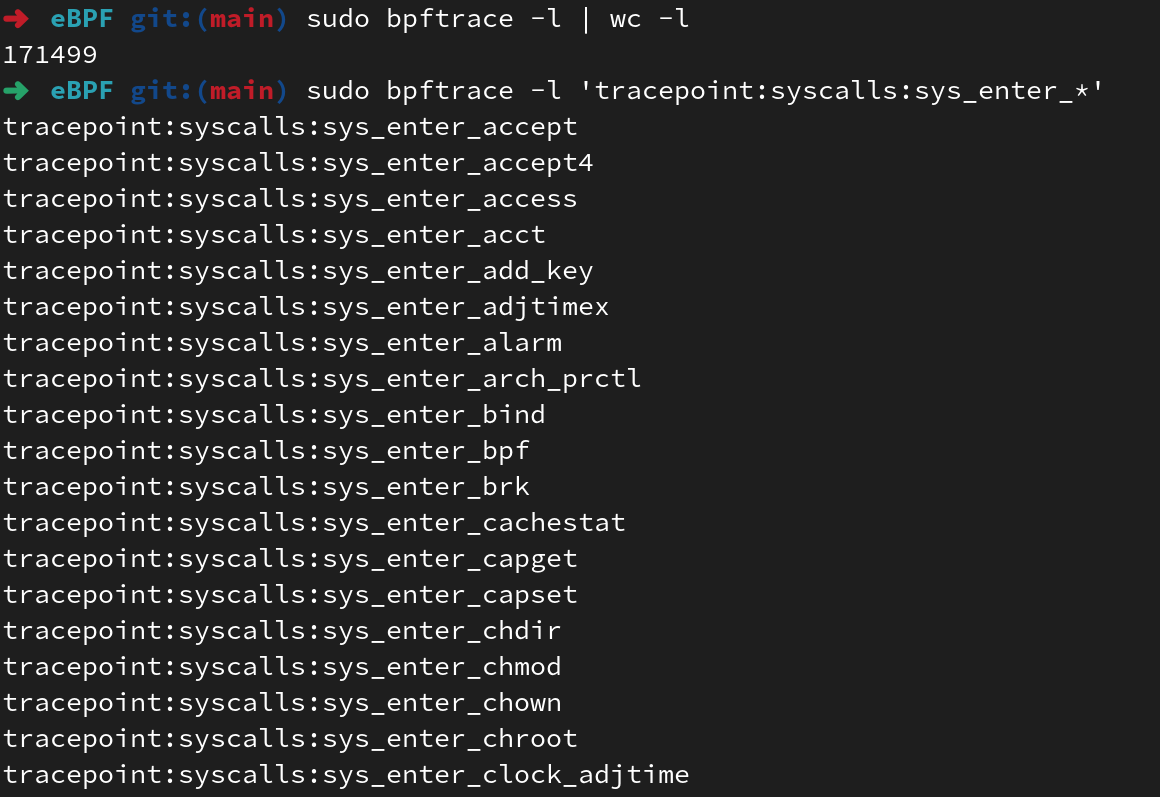 |
| Command output using bpftrace list option |
bpftrace -e: Now what about if I want to trace a specific syscall so every time that syscall runs I would be able to trace it? Let’s take /usr/bin/cat. First we figure out what syscall this is actually running because of course in Linux there is more than one way to do things; for example open(), openat(), etc. We would run strace to see what function is actually being called- it’s openat. Now let’s just hook it with bpftrace and see if we can print out every time the system opens a file with that syscall.
Of note, this is a great detection engineering technique for looking at the system calls rather than the program because this detection could very well catch other programs that open a file using this same syscall.
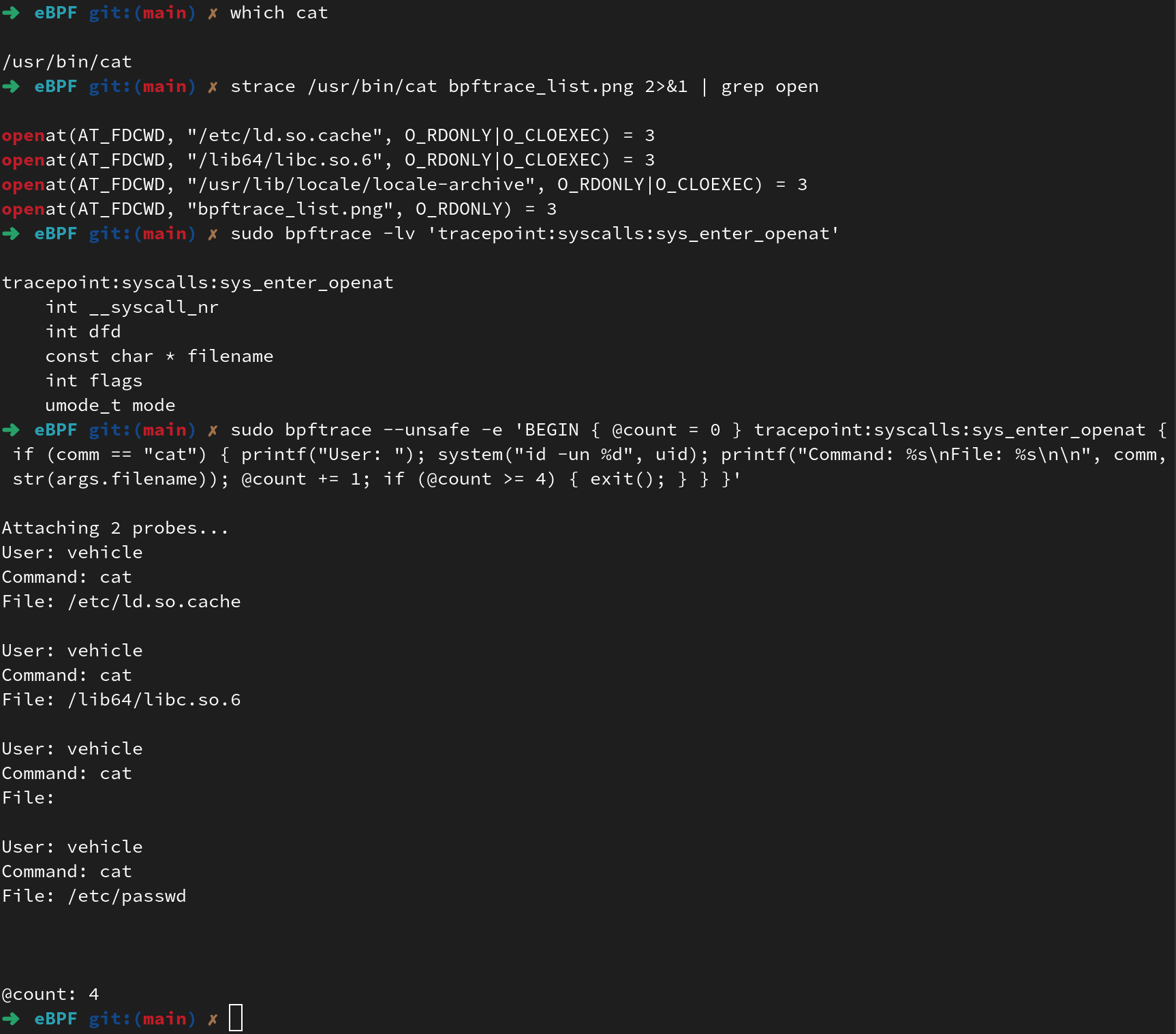 |
| Command output tracing cat syscall openat with bpftrace |
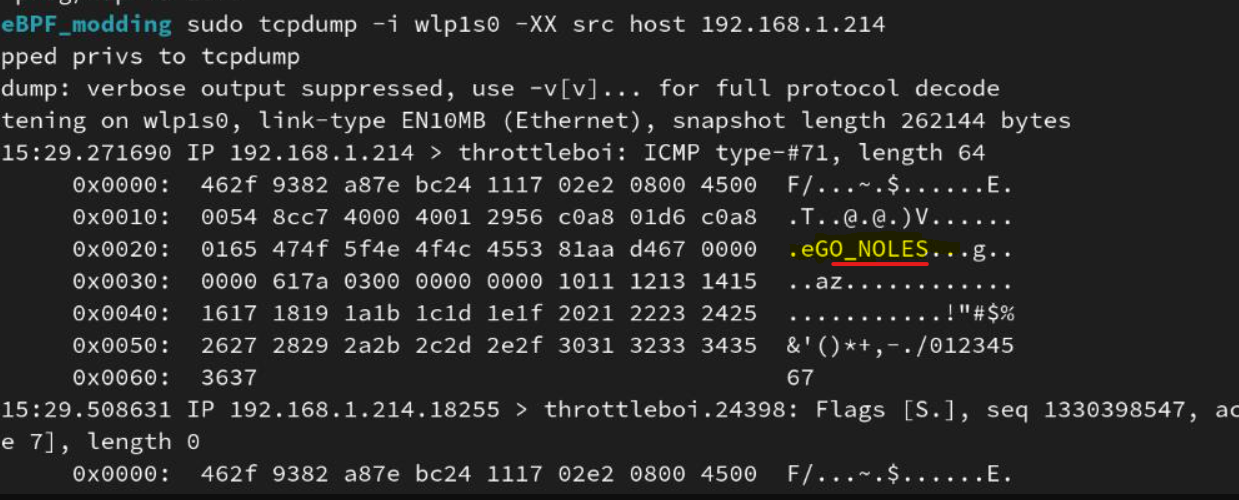
libbpf C Library: Actually let me take this one step further by writing a brief C program, with the libbpf C library to actually modify an incoming network packet’s payload data. After writing the program I compiled it using ecli & ecc by eunomia.
In the below screenshot I have successfully modified the first 8 bytes of an incoming ping request to “GO_NOLES” with a compiled eBPF program.
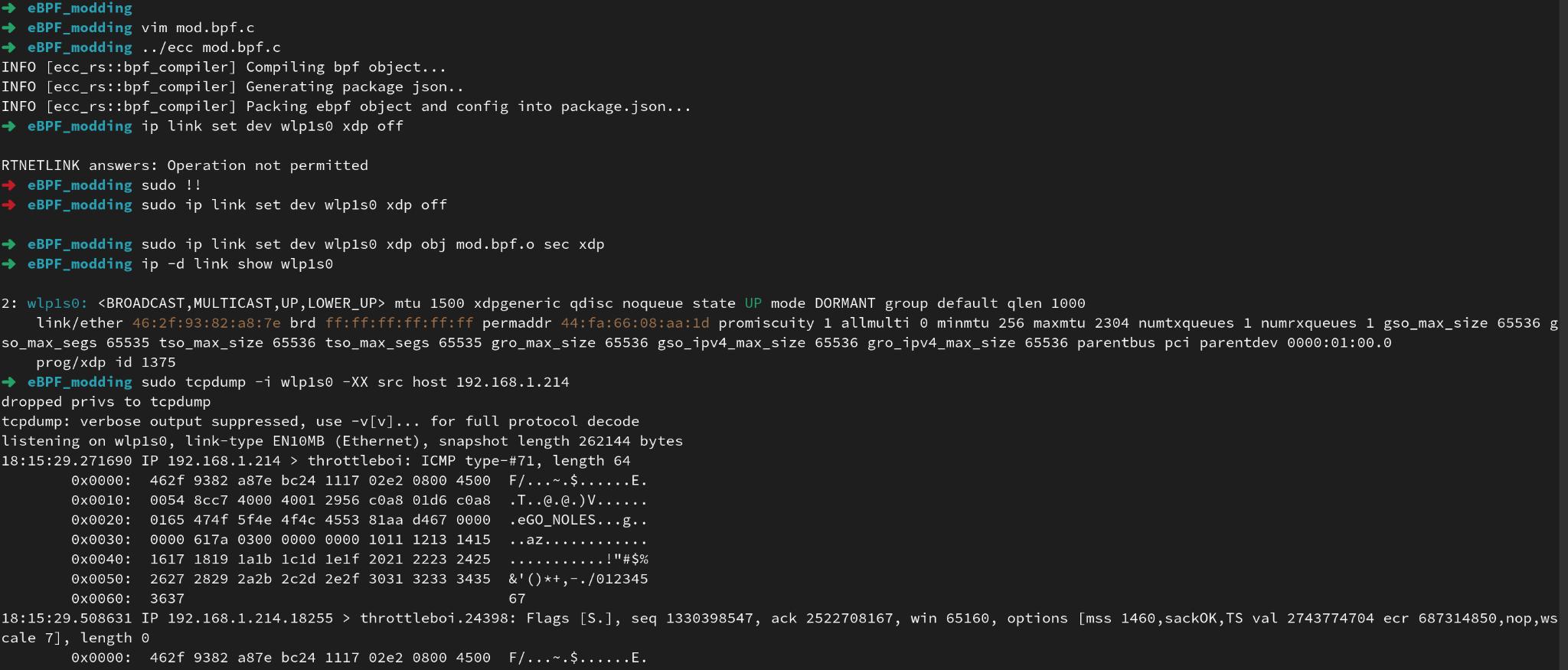 |
| tcpdump output of a modified packet using the libbpf library |
What’s Next
There are also so many other concepts we haven’t begun to delve in to like BPF CORE (Compile Once - Run Everywhere)9, maps, the verifier, tail calls (chaining different eBPF programs), eBPF tokens (like auth tokens), and so much more! I may do more posts on those separately.
There is also the darker side to this topic where sysdig and RedCanary wrote on how to bypass eBPF monitoring hooks. And then there are the numerous vulnerabilities in eBPF implementation.
The End?
Ok I have to cut this post off because it has covered wayyy more than I originally wanted to write on but that’s how it goes sometimes!
I am always learning and refining my understanding of eBPF, and I welcome feedback! If you see any errors or have insights to share, please don’t hesitate to reach out. I am also actively looking to network with other professionals in this field so if you’re passionate about kernel programming or security and are interested in collaborating or connecting, let’s chat. And if you enjoyed this post, be sure to say hello at the next conference.
The Players
I want to share how to get more involved because though RTFM is always a good start I believe the best way to learn is to get more involved in the community supporting it
- People: Brendan Gregg10, Alex Maestretti, Thomas Graf
- Blogs: Brendan Gregg’s Blogs, Teodor Podobnik’s eBPFChirp, Isovalent’s blog
- Talks: First exploration of eBPF as a Security tool | BSidesSF 2017 and Linux rootkits using eBPF | DEFCON29
We love FFRDCs! ↩︎
BPFDoor from 2022 - https://freedium.cfd/https://doublepulsar.com/bpfdoor-an-active-chinese-global-surveillance-tool-54b078f1a896 ↩︎
https://www.spinics.net/lists/xdp-newbies/msg00181.html and https://docs.ebpf.io/linux/program-type ↩︎
Take that argv trick! https://www.uofr.net/~greg/processname.html ↩︎
https://docs.cilium.io/en/stable/reference-guides/bpf/resources/ ↩︎
How do we translate this into DFIR tools like Volatility so you don’t constantly have to rebuild Linux kernel profiles? ↩︎
Brendan Gregg wrote the book on BPF, https://www.brendangregg.com/bpf-performance-tools-book.html ↩︎